ChatGPT(GPT-3) 後の進化の予想:自然言語が原始言語と呼ばれる日

目次:
(0) 最尤推定・パラメーター推定
(1) 深層学習とKL情報量について
(2) スクリプト意味論について
(3) チョムスキー階層と複雑性クラスについて
(4) ヴィトゲンシュタイン前期後期による言語哲学の分類について
(5) 自然言語が原始言語と呼ばれるまで
※数式が面倒な人は(1)の途中の”中国語の部屋”の部分から読んでください。
GPT-3 Chatはチューリングテストをクリアしているとも言える会話のクオリティを幅広いトピックで行うことができます。これには驚きを隠せません。今後GPT-3以上の自然言語処理ができるために、あるいはこれからの方向を理解するためには何を基準に考えればいいでしょうか?この議論は自然言語処理、統計、言語哲学、オートマトンの基礎的知識のみに基づいて話をしていきます。
結論としてはChatGPTは高次元の”中国語の部屋”であり、表象を欠きます。表象をつけるスクリプト意味論や心像意味論といった昔からある議論は最新の人工知能開発の動向と一致しています。

人工知能や機械学習に関しては、自分も含め専門外からもさまざまな人から意見があり、ある種その外野領域の中でも興味深い意見の文脈をまとめさせて頂き、暇つぶし程度になれば幸いと思います。多くの人の人工知能に関するイメージが本記事でかなり鮮明になればと思います。
最尤推定・パラメーター推定
この世界の多くの観測できる数字やデータは何かしらの確率的なルールに基づいて、たまたまこの世に出てくることにしましょう。そう思うしか我々にはできません。さらにもっと諦めた考え方として、その確率的なルール、つまりは真の分布も知ることは永遠に叶わず、得られたデータから推測するしかないのです。これは基本的な統計でも最先端のAIでも変わらない仮定です。観測できる数字やデータを確率変数と呼びます。
本当の確率分布など全知全能者しか知らないので、近づけることが目的となります。確率分布の種類を仮定し、そのパラメーター(母数)を推定をすることで真の確率分布を予測します。
これをパラメーター推定と言いますが、観測できた現象から真の確率分布を予想するのは次のような例があります。 これは最も尤もらしい分布をサンプルから逆算することから最尤推定と言われます。一番簡単な例をあげましょう。

片側が重いコインがあり、投げると一定の確率pで表が出ます。何回表が出るか実験し、pを推定しましょう。
何回表が出るかという数字は二項分布に従うはずです。つまり、二項分布のパラメーターpを推定します。
さて、5回投げて3回表が出ました。
仮定した二項分布の確率密度(質量)関数より、5回投げて3回表が出る確率は (5C3) p³ (1-p)² = 10(p⁵-2p⁴+p³)です。
最も高い確率でこれが起こる分布のもと、この現象が起こったと仮定します。これが最大になるのは、この微分が0の時なので
5p⁴-8p³+3p²=0の時、p = 3/5とp=1,0。
p=1,0は最小の時なので、p=3/5です。
つまり二項分布だろうという仮定と、この3回表が出たという現象から逆算できる一番尤もらしい、一番真だと思われる確率分布はパラメーターpが3/5である二項分布だというわけです。
確率分布がわかれば、次7回投げて何回表が出るのか予想できます。
誤解を恐れず言えば、このパラメーター推定を多次元、つまりは沢山のパラメーターや確率変数で行なっているのが深層学習です。
パラメーター推定という言葉をもっと身近に感じたいのであれば、もっと簡単なケースの線形回帰分析が良いでしょう。例えば、日本人の身長体重数十件のデータをグラフにプロットして直線を引くだけです。
この場合は真の法則は単に身長と体重が簡単な1次方程式の直線グラフであると仮定して、身長から体重を予想できるようにするパラメーター推定です。直線y=ax+bの傾きaと切片bがパラメーターです。
まーここでは統計や機械学習が何かしら真のグラフや図形に近いものをパラメーター推定で求めたがっていることを自分は伝えたいだけです。
次のセクションで意味がわかりますが、深層学習は多変数の回帰分析で曲線を使うもの、つまり「非線形重回帰分析と同じ」という言い方をする人もいます。
「アレ?さっき深層学習は最尤推定の多変数(多次元)バージョンと同じだって言ってたじゃん。結局どっち?」って思うかもしれませんが、有名な最小二乗法と言う基準で回帰分析で線を引くことは、誤差が正規分布と仮定した最尤推定と一致するので、どちらの言説も同じことを言っています。
深層学習とKL情報量
まずGPT-3そのものである深層学習について最短で分析したいと思います。深層学習とは基本的にニューラルネットワーク・多層パーセプトロンと呼ばれる機械学習のことです。丸で描かれる各ユニットが変数になっています。つまり次の図では入力層は 3個の変数からなるベクトル、出力層も2個の変数からなる出力です。
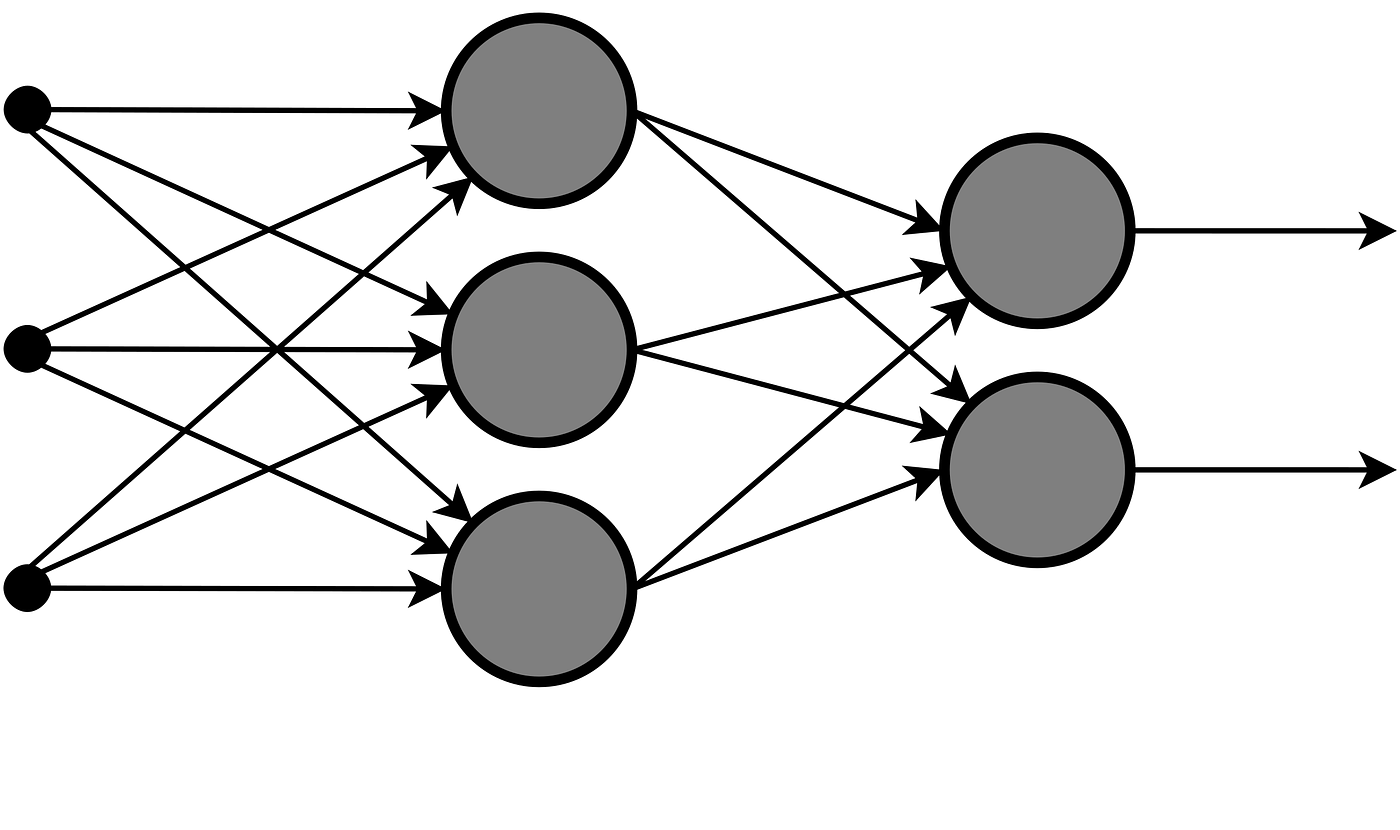
上の図のニューラルネットワークの使い方の例としては、身長・体重・体脂肪率から男女の予想をする場合、[身長, 体重, 体脂肪率]をベクトルとして入力層に上から順に3つ入れ、出力層を男[1,0]か女[0,1]にするなどが考えられます。
下図の通り、各ユニット(丸)に入る入力x_iは、重みw_iに掛け算されたのち活性化関数φというテキトーな関数に入れられます。こうして生まれた値φ(・)は次の層y_kへの入力として前述のx_iと同じように扱われます。
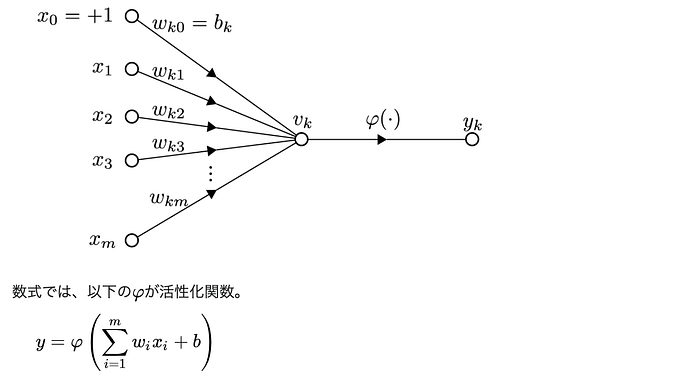
それぞれのパスに付けられた重みが推定対象のパラメーターです。
1960年代に考案されましたが、当時は活性化関数がなく、単純な回帰分析と同じく線を引く問題しか解決できませんでした。
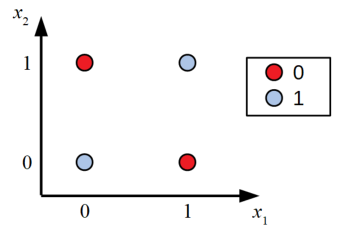
パーセプトロンはただ単に多層にしても線を引くことしかできません。なぜなら線形写像に線型写像を重ねても線形だからです。f,gにいかなる一次関数を入れてもf(g(x))は線形です。これはXOR問題と言う単純な分類問題すら解決できないことを意味します。下の図を線を数本引いて赤と青を分けて見てください。
そして中間で層から次の層に伝達する関数(活性化関数)に非線形な関数(シグモイド関数など)をテキトーに入れることによって、複雑な分類問題も解けるようになるはずでした。途中に非線形な関数が入ることであらゆる線や面が引ける、つまりは任意の関数を近似することが可能になると言うわけです。
具体的にどうやってパラメーター推定をしていって、線や面やグラフができていくのかというと、出力層から出た予想と実際の値の差、つまりは誤差を最小化していくようにパラメータを変えます。これは勾配降下法と言う方法の亜種で最小値を求めていきます。
勾配降下法は、グラフの最小値を求める際に、点を動かしていき、勾配(微分)の方向と進行方向が一致すれば進んでいくという手法です。ゴールは微分が0になる点ですね。

「は?周りくどいことせずに微分が0になるところ方程式解いて見つけろよ」
って思いますよね?けど、1変数関数の単純な関数ならまだしも、多変数で得体の知れない関数を機械的に微分なんてできないですよ。各点での微分係数は割と近似的に求まりやすいので、それを使って勾配を求めます。この偏微分計算を多変数関数に対して効率よくやる方法が誤差逆伝播法です。
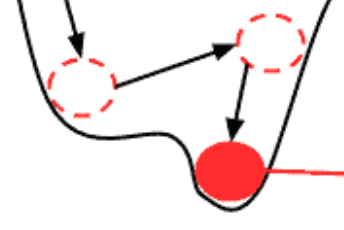
それと、上の図にもありますが、局所解と呼ばれる窪みにハマってしまう場合があり、これだともちろん性能が悪くなります。ワンチャン運のいい入力が続いた場合に窪みの外にポーンっと出れるようにワンチャン仕様にします。亜種である確率的勾配降下法が採用されている理由です。
誤差逆伝播法
誤差逆伝播法で出力した予想に対して教師データ(正解)がずれている場合、このズレを逆方向に伝播し、引き起こした可能性の高い関数(ユニット同士のコネクションの重みづけ)を更新します。偏微分計算をします。

多層の場合は、合成関数の偏微分の連鎖律を用いて簡単に計算できます。
しかし、多層にしてしまうと勾配が逆伝播の途中で消失してしまい、肝心の学習である誤差情報によるパラメータ更新がうまくいきませんでした。つまり多層にしてると、どっかの活性化関数の微分が0に近くなってしまうケースで、逆伝播がほとんど止まってしまうのが問題だというわけです。
「は!?さっきは微分が0の最小値のところ探してるって言ってただろ!?微分0になったらおめでたいだろが!?」って思う人。それは真っ当な疑問ですが、誤差がなくなり微分が実際に0になるのと微分計算の仕方に問題があって0になるのでは事態が異なります。
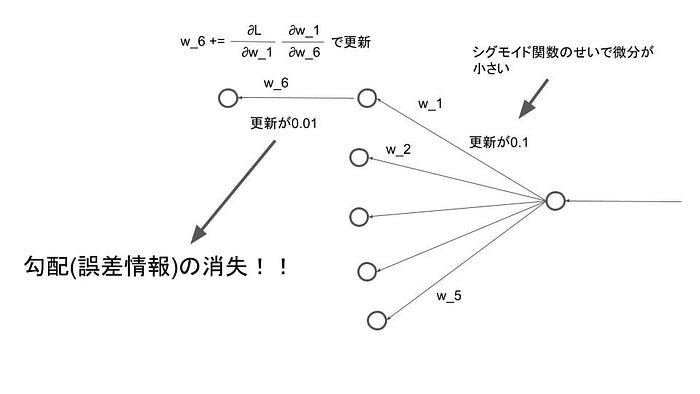
誤差逆伝播のケースの中で、全体的に情報が消失するケースがあり、それは活性化関数の選び方を間違った場合です。活性化関数として昔主流だったシグモイド関数は微分後の導関数の最大値が0.25です。ちょっと運が悪ければすぐに0.1とかになります。これが多層になってかけ合わさるので運が悪いとすぐ0.0001とかになります。全体的にシグモイドは導関数の値が小さすぎて出力層からの逆伝播がどんどん小さくなってしまいます。なので、tanh関数やReLU関数を代わりに使って無駄に情報が消えてくのを防ぎます。端的に言えば、”テキトーな非線形関数”だとダメだったという話です。最近ではReLU関数が一番人気です。
というわけで、無意味な勾配消失問題を解消したのちに、ちゃんと勾配を消失させるのが深層学習の活動というわけです。
2011年ではジェフリー・ヒントンがオートエンコーダを導入し、この勾配消失問題が改善しました。こうして勾配消失問題の種々の解決により、始まったのが深層学習です。よく深層学習はSVMと違い特徴量を自動で選ぶようになったからすごいと説明されますが、それはSVMと比較した結果であり、過程と結果を両方表すのは勾配消失問題の解決です。
KL情報量
このようにして、”誤差”を減らしてく学習、つまりはパラメーター推定が可能になったわけですが、この誤差はなんなのでしょうか?
最初に戻りますが、これは本質的には真の確率分布との誤差です。観測できたデータから、それが従う本当の確率モデルを知ることができれば最も高い精度のものが作れますが、全知全能者しか知り得ません。
この真のモデルMと今のモデルの誤差は、分布同士の違いを表すKL情報量で定義できます。
KL情報量はSanovの定理から、分布同士の違いの数ある定義のなかで最も良いと考えられます。Sanovの定理を簡単に言えば、KL情報量の最小化は真の分布に指数関数的に近づけることを意味します。(こちらが大変わかりやすかったです)
そして変数変換に対して普遍性があります。
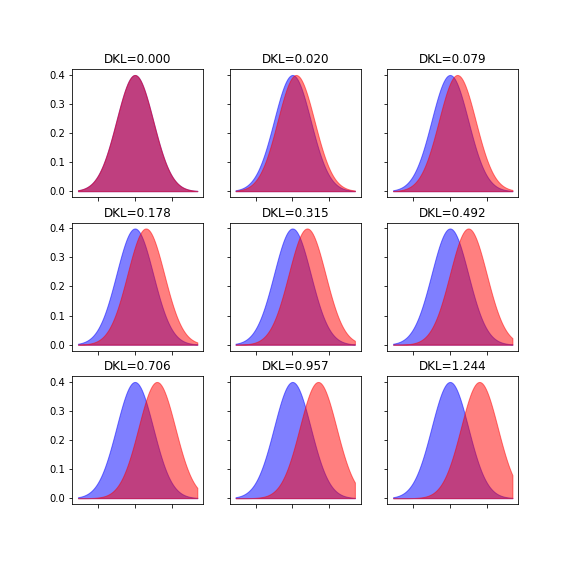
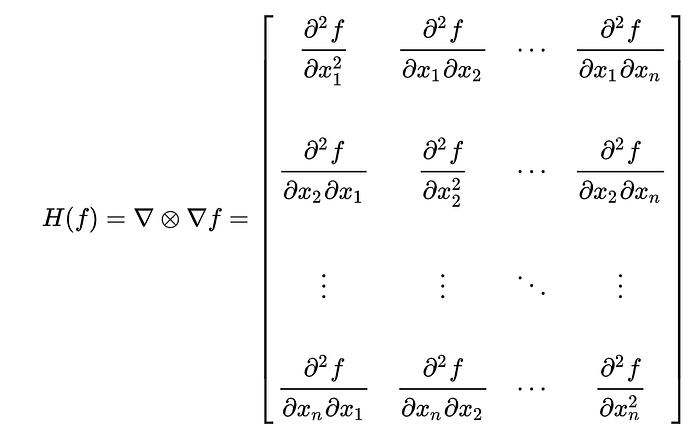
ではKL情報量が最も小さくなれば良いわけですが、それは最尤推定と同値であることが確認されています。なので先ほど深層学習はパラメーターの最尤推定と同じであるとしたわけです。KL情報量が最も小さくなる場合は何か考えましょう。真のモデルは多変数の確率分布です。KL情報量は多変数関数で定義可能です。このKL情報量 k(x1,….xn)の最小値問題は、大学数学で習う通り、ヘッセ行列を使って判定可能です。KL情報量のヘッセ行列はフィッシャー情報行列と呼ばれます。
最小値問題のいつもの解き方をそのまま当てはめれば、kl情報量の全ての変数での偏微分が0かつ、ヘッセ行列(フィッシャー情報行列)が正定値で極小です。
フィッシャー情報行列(情報量)にはKL情報量の最小値問題に関わるためか面白い性質があります。クラメール・ラオの不等式を満たすことが知られています。

不偏推定量(つまり特定の条件のパラメーター)の分散・ばらつきがフィッシャー情報量の逆数よりは小さくできないことを表しています。
推定したいパラメータのバラつき(ヴァリアンスと呼ばれます)が毎回の推定で真の確率分布から偶然ずれてしまう誤差が小さいことは、性能の安定性につながります。というよりは性能そのものと言っていいでしょう。
フィッシャー情報行列からは教師データーとパラメーターの関係がわかることから非常に重要です。ニューラルネットワークの忘却問題の解決もこれによってなされたそうです。 フィッシャー情報行列からさらに情報幾何学という分野を創始したのが甘利俊一らしいですが、難しすぎて書いてあることが理解できませんでした。
さて、GPT-3はパーセプトロンの中でも最もパラメーターの数が多い部類で、それは1750億に達します。この数が多ければ多いほどいいのでしょうか?
答えはNoです。先ほどのコインの例で本当に真の分布が二項分布である場合、不要な確率変数を定義して間違った確率分布の種類を入れれば、確実に精度は下がるでしょう。つまり本来正しいパラメータの数は真のモデルのパラメータの数です。もちろん自然言語の意味を表す確率分布に幾つパラメーターがあるのかは誰にもわかりません。手探りとは言わずとも地道に探していくほかないでしょう。
中国語の部屋
ここまでの説明はなぜニューラルネットワークが普通の多変数での最尤推定や重回帰分析(多変数での回帰分析)より、現在主流になっているのかを説明できていません。
「なぜディープラーニング?」
「結局パラメーター推定するなら、プロの力で真のモデルの確率分布の種類を選択して、正確にパラメータ推定した方が圧倒的に精度高そうじゃない?」
と言った疑問に答えていないでしょう。
これは自分がこの記事で、単純な回帰分析のようなものから確率変数の数を増やして多変数にして、それに伴って増えたパラメータ推定を1個のノリで続けるかのような書き方をしてしまっているからですね。
実際は真の多変量確率分布のモデルの構造どころか幾つパラメーターが要るのかすらわからない中で、大量の確率変数とパラメーターの絡む最尤推定というのは異常に難しいものとなるでしょう。何より、勾配降下法でパラメーター推定するのであれば、微分の計算が多次元であれば全然終わりません。誤差逆伝播なしに、多次元でのパラメーター推定は難しいでしょう。
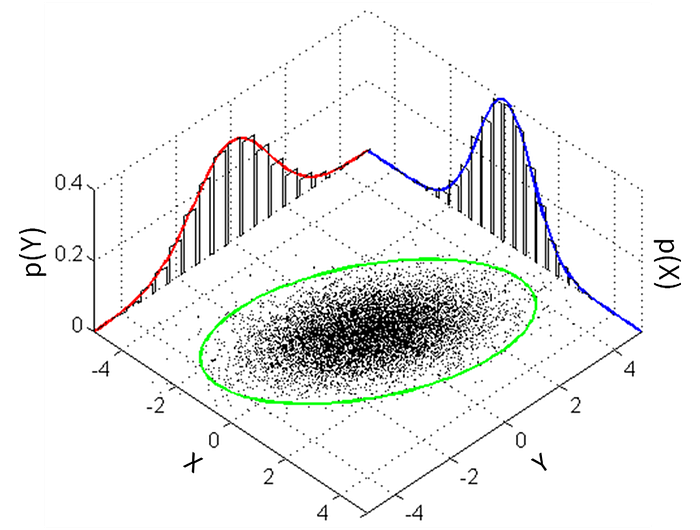
文章生成などでは、確率変数となる単語は単にランダムに現れるのではなく、文法と意味に束縛されて出現します。確率変数同士は非常に複雑で規則的な関係性を持って従属しています。
ニューラルネットワークの場合は、大量にパラメーターが用意された後重要なものが自動で残っていくという、(SVMと違い)特徴量が自動で選択されていくというよく言われる性質の他に、とにかく微分の計算が効率的であることにより、高度で超複雑で非線形な統計モデルが考えられないほど短時間で終わることは特筆すべきです。
さて、このように深層学習によってkl情報量が最小化され、高次元(多変数)の図形である確率分布が生まれます。この高次元のオブジェクトはAIでしょうか?

統計に基づいて返信すべき内容を返却します。この高次元オブジェクトは言語を理解しているのでしょうか?
昔、中国語の部屋という思考実験がありました。部屋に中国語を全く知らない英国人がいて機械的なマニュアルに従って中国語の質問に答えるというわけです。この部屋には中国語を理解するプロセスがあるのでしょうか?おそらくないでしょう。このオブジェクトは高次元の中国語の部屋といえます。GPT-3は1750億次元の中国語の部屋です。
では、この言語の理解とは一体なんなのでしょうか?
つまり「意味」の意味について考えます。
スクリプト意味論について
昔は言語(英語などの自然言語)の意味を単語や構文を解析するだけで一意に特定できると信じられていました。そのため、シソーラスという階層型の辞書、構文解析器、そして古典論理学が自然言語処理や人工知能領域の道具でした。
シソーラスに柴犬が犬の一種として記録され、
私にとって犬は可愛い=>私にとってうちの柴犬も可愛い

などという推論マシンができるというわけです。こういったものを組み合わせることで、自然言語処理や知能システムが辞書と論理学の力を使って強力に推論できるというわけです。(これをモンタギュー意味論といいます)
しかしながらどうでしょう、シソーラスにおいて「意味」の意味とはなんでしょう?
意味とはネット辞書では「言葉が示す内容」となっています。

「内容」を辞書で調べると「文章や話などの中で伝えようとしている事柄。意味。」となっています。シソーラス上層部にある抽象単語、「意味」「内容」「論理」「表現」「理解」などではお互いに循環参照してしまっています。
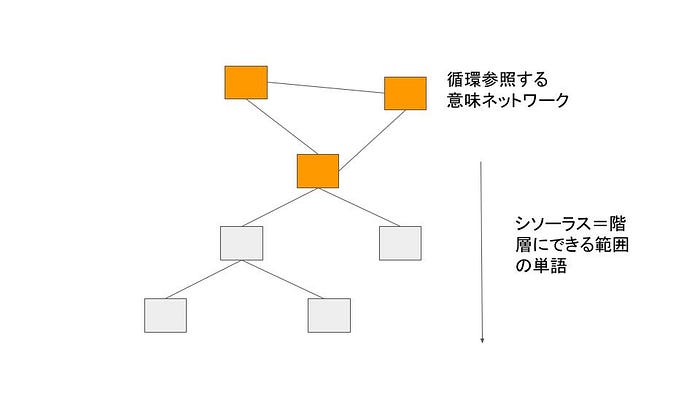
これは、言語や文章の意味を、構文と単語と辞書的意味を一対一対応させていくだけで解析できると思っていた人には大変都合が悪いものです。結局多くの場合最終的な「意味データ」や論理のようなものに帰着できないわけですから。
論理学をベースとした意味論や知能システムは限界を迎えます。この時この言語の意味論にスクリプト意味論というのが登場します。言葉の意味というのは辞書的な意味の構成物ではなく、そのスクリプト(台本)にあるのだと。特定の場面を表す映像が言語の意味だというわけです。
自分は自然言語処理の仕事をしていた時に、最初この考え方に対して非常に軽蔑的でした。深遠な意味を持っているであろう抽象的で難解な本などが台本的映像に帰着されるとは思えなかったのです。意味ネットワークの数学的なオブジェクトとして意味が存在し、論理によって演算可能だろうと思っていました。台本が文の意味であるなどというのは限定的なケースだと思っていたのです。しかしながら、今は言語は完全に脳内の表象(イメージ)と感覚を受け手に伝えるためのものであり、難解さや抽象度にかかわらず例外はないと考えています。
先ほどのシソーラスと意味ネットワークはあくまで記号の世界で閉じていました。記号で記号の意味を定義しようとしていたため、その意味には外部性がありませんでした。スクリプト意味論の場合は記号とその集合である文の意味は人間の(伝え手)の脳内にあるイメージ&感覚であるため外部性があり、先ほどの循環参照は解決されるわけです。これで記号は意味を持ちました。逆にいえば、この方針は人間の脳という複雑さに向き合うアプローチを取ることを意味します。これは後述のメンタルスペース理論ではより鮮明となります。
スクリプト意味論を実際にコンピューターで実行可能にするのがフィルモアのフレーム意味論と言えます。動詞をスクリプトの中心に考えて、スクリプト(台本)を定義し、そこに登場する役割のものを当てはめていくという処理です。
ここで何が言いたいかといえば、自然言語は脳を実行環境・コンパイラにした言語であり、脳のための言語で、その機能・意味は脳内にイメージを作成することだということです。そして、機械学習による自然言語理解のタスクにおいては、文からイメージ(画像・動画・音声)を正確に作ることではないかと示唆されるということです。このことは述語論理学ベースの方針を排除するものではなく、融合していくだろうと考えています。
チョムスキー階層と複雑性クラスについて
さて、人間の言語である自然言語の意味をマシンが知ろうとするわけです。プログラミング言語はマシンの動きを曖昧さなく定義するわけですが、これは自然言語と違うのでしょうか?
基本的にプログラミング言語も自然言語も効率的に一意に構文解析することができます。これはこれらの構文が二番目に簡単な言語レベルである文脈自由文法にほとんど属するからです。言語の複雑さと表現力の階層はチョムスキー階層と呼ばれ次のようになっています。書き換え規則の制限のキツさによって階層が決まります。制限がきついほど何もできなくなります。

では、この二番目に単純なものにほぼ属すると言えるプログラミング言語と自然言語は実際そのように同じような単純な意味を持つものなのでしょうか?意味分析と構文解析が違うためそのようになりません。
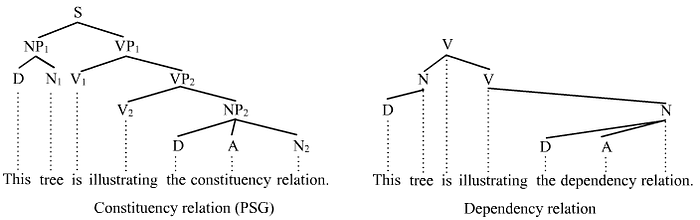
プログラミング言語やアセンブリ言語によってできるプログラムは実際チューリングマシン全体で任意の動作ができます。そのためその動作から意味を考えれば、その意味を文脈自由文法で表すのには無理があるでしょう。そして、プログラミング言語は文脈自由文法を実際には少し拡大したものになります。少し拡大というのは、文脈自由文法はスタックを有限オートマトンに付けただけになりますが、実際のプログラムの挙動はメモリもいじることができ、プログラム自体もメモリに載って参照の対象になっているところです。
余談ですが、正規表現は正規言語を少し拡大させたものです。aaaをaを3回繰り返したものだと認識するのは、正規表現のオートマトンには記憶能力がないので不可能で、ついでに言うと文脈自由文法もこの回数記憶付きの反復を認識することができません。ちょっと拡大と言いますが、言語階層としては大きく飛び越えて拡大してしまっています。
自然言語についても、言語自体の構文解析は比較的単純にほとんど文脈自由文法を使って解析することができます。しかし、構文解析後の意味は先ほど言った通り脳内の表象です。
「芸術は爆発だ」は構文解析は「名詞 は(助詞) 名詞」と簡単ですが、伝え手の意図する意味には大量の注釈を伴うと思われます。構文解析後に”意味データ”まで書き換えるためには、0型文法である任意の書き換えが必要になりそうです。
この階層では2型と0型くらいしか気にする必要がなく、少し分類として粗いので、もう少し複雑に分類してみましょう。複雑性クラスはチョムスキー階層が「何ができるかできないか」で分類しているのに加えて、「どのくらいの時間でできるか」でも分類をしています。
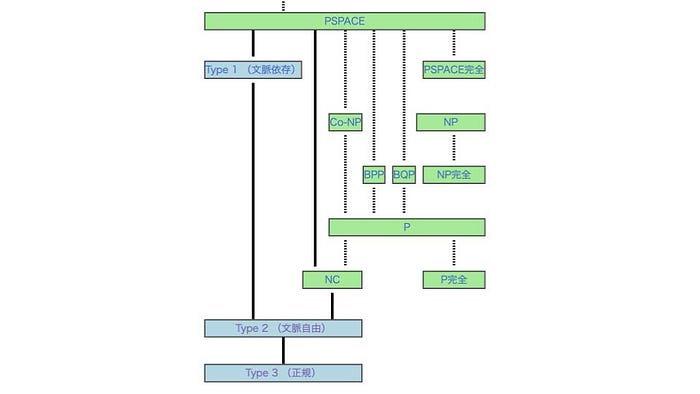
おそらく、このP問題あたりに、人間の脳内の表象を最尤推定するという課題があるだろうと願います。そうであれば、コンピューターは人間の言語を理解し、映像を生成できます。
今まで人工知能について、内側の説明、外側からKL情報量による外観、チョムスキー階層による外観によって見てきましたが、もっと外側から見て見ましょう。言語哲学です。

ヴィトゲンシュタイン前期後期とフォコニエ
ヴィトゲンシュタインは大学ではありません。が、前期と後期に分かれて哲学者を募集しています。20世紀で最も偉大な哲学者の1人と言われていて、彼がその考えを変える前の言葉「語り得ないものには沈黙しなければならない」頻繁に語られています。
簡単に言えば、ヴィトゲンシュタインは若い時、世界は事実の総体であり、言語はその背後にある論理空間の写像で一通りの意味を持つと考えていました。この時、例の名言を本の最後としています。「非論理的思考というのは存在しえない」とすら書いています。老いてからのヴィトゲンシュタインはその考えを大きく変え、言語は生活様式であり、子供のボール遊びのようなルール変わり続けるゲームだと言い始めました。
若いヴィトゲンシュタインはカントとフレーゲから影響を受けたと思われます。フレーゲこそ、言語に関して構成性原理を提唱し、文の意味はその構成要素の論理の合成和であると言っていたのです。つまり言語の意味というのは論理的な意味に一対一対応であるというわけです。そして、ヴィトゲンシュタインは論理的な言語活動で行えない哲学活動を無意味と断じたカントと結論を同じくします。
前期ヴィトゲンシュタインはクワインとクリプキに影響を与えました。クワインは構成性原理を否定して全体論、つまり文は合成和以上のものであると考えましたが、存在するということは論理学的な存在子の項になりうるということだと解釈し、言語は全体論ながらシステマティックで論理的であるという立場を崩しませんでした。
後期ヴィトゲンシュタインはその論理から離れた態度によって、当時の理屈っぽい哲学界隈では完全に浮いた状態になっています。言語の意味は生活様式としての言語の使用にあると考えています。言語の意味が一人一人によって大きく異なることを認めており、前期組の考え方を退けました。一方で言語の意味が表象や心的過程にはないと考えているので、その後の哲学者たちからも浮いています。
認知言語学の走りであるフォコニエのメンタルスペース理論は後期ヴィトゲンシュタインの系譜にはないですが、前期組の否定の系譜にあると言っっていいでしょう。メンタルスペース理論では全ての言語はその受け手の脳内のメンタルスペースにおける表象の生成を行う命令です。「赤茶色の犬が公園を首輪なしで歩いてる。」は命令文であり、この様子を脳内に表象としてイメージせよということです。このことで、自然言語はプログラミング言語のように全ての文は機械に対する命令となり、その機械とは脳=メンタルスペースです。
チョムスキーは言語の意味(生成文法)を脳に帰着させましたが、あくまでシステマティックで普遍的な文法が脳にあり、言語の意味はシステマティックであるという立場でした。
それぞれの哲学者・言語学者が何を言ってるのか、雑に要約します。(自分が原著の翻訳か哲学者による解説本を読んだ範囲で話します。ヘーゲル・ショーペンハウアー・フッサール・ハイデガ・ドゥルーズは重要なようですが、自分には難解でとても理解できず挫折したので割愛します)



大胆にもバッサリ言語学者、言語哲学者をヴィトゲンシュタイン前期組とポスト後期組に分けると、後期組はフォコニエだけ。真ん中くらいにクワインとカントがいる感じです。他は全員前期組ですね。
前期組は錚々たるメンバーです。一方後期組はなんか優しそうなオッサンのフォコニエのみで前期より雑魚そうですが、しかし、言語の意味はフォコニエのみが自然言語の意味がそのコンパイラ/実行環境である脳に依存していること、その複雑性と神秘性から逃げようとしていないのです。この系譜は認知言語学や心像意味論に引き継がれています。
自然言語が原始言語と呼ばれる日
自然言語の意味がイメージや映像にあるとして、GPT-3が意味を理解するためにはどうしたらよいでしょうか?
まー、そのままですね。Stable Diffusionみたいな画像生成を、映像にしてさらに入力の意味に即して正確に行えば、これを解釈したり連想したりすることができます。これはいつも我々が行ってるやつです。映像生成=>映像解析=>連想映像生成 or 意味論理計算 => 返答出力
のような感じであれば人間と近い動きをしそうです。しかしここでひとつ気になるのは、これは単に映像を中間層にしたニューラルネットワークであり、特に今のGPT-3と変わらないのではという疑問ですね。
しかし、この映像出力に対しては、ニューラルネット以外の演算を交えて行うことができます。映像出力の改善は物理諸法則に基づく微分方程式によるシミュレーションが適用できますし、ニューラルネットの記号世界外の知識との接続を作ることができます。なので、高い可能性で改善の道筋につながるでしょう。シソーラス・論理ベースのアプローチとの融合の可能性もあると考えられます。
もう一つの疑問は、そもそも人間に近づけるのがよい方向性なのかどうかです。
やはり、端的に”意味の意味”や映像的な時空間の感覚を持つ機械はそれを持たない機械より優れているとは言えるでしょう。外界の知識を会得する手段として、人間の自然言語よりもよいものがあるのであれば、人間に近づける必要はないのかもしれません。さらに言えば、人間の自然言語をより機械フレンドリーにする手もあります。この記事の文脈で言えば、深層学習でイメージを生成しやすい言語ということですね。
例えば、論理ベース(前期組)の自然言語改革のアプローチとして人工言語Logibanがあります。これは述語論理(命題論理の拡張)に帰着可能な自然言語風の人工言語です。
元々自然言語は比喩が多いだけでなく、同音異義語などダブりが多いため、機械のエラーを引き起こしやすいです。機械語に解釈しやすい人工言語を作る試みですが、音声認識が発達してない時代でコンピューターに理解しやすい言語を話す理由が少なかったので、Logibanは研究程度の規模の利用人数にとどまりました。しかし、人工知能がこれからあまりにも支配的になる場合は3通りのパターンが考えられます。
(1) 英語がより強くなる
(2) 人工言語が強くなる
(3) マイナー言語が強くなる
(1)は圧倒的にコーパスの数が多い英語がデータの量で圧倒し、英語がAI世界でも中核をなす言語となることです。英語ができればコンピューターでおおよそやりたいことが全てスムーズにできる世界です。個人的には短期ではこれが一番可能性高そうだなと思います。
(2)は機械との接続効率の良いLogibanの改良のような人工自然言語が英語のAI性能を圧倒し、主流になる世界です。多くの人が英語と人工言語二つを学ぶのは大変なので、人工言語が英語を共通言語の座から引きずり下ろすことになるでしょう。英語は他と変わらない「原始言語」となります。
(3) 自然言語理解する機械の効率や機能を増やすことにより、日本語のようなマイナー言語が英語を超えようとする動きです。例えば日本語であればアニメーションと日本語がセットになっているコーパスが大量にあるので、日本語=>アニメーションの生成タスクにおいて英語を上回ることができるかも知れません。例えばこのようにして英語を上回るAI性能の言語になることを目指す動きが出るかもしれません。
タイトル「自然言語が原始言語と呼ばれる日」は少し煽り気味ですが、激しい言語競争、言語主導権争いの第二幕になるのではないかなということを伝えたかったところです。
著者: 極度妄想(しなさい)
https://twitter.com/leo_hio
Ethereumの暗号学的な性能向上を専門にしています。
財産権がEthereumやBitcoinで守られて、政治が機械学習モデルの独裁になる社会が、たまに頭をよぎらなくはないです。
